

圖 2018年6月,在北京舉辦的IEEE人工智能與控制論國際研討會,IEEE SMC學會、中國自動化學會、中科院自動化研究所等專家在對區塊鏈、人工智能等概念的熱炒降溫
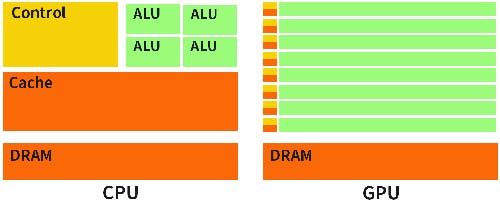
圖 GPU比CPU有更多的邏輯運算單元(ALU)
從GPU到FPGA和ASIC芯片
200六年己前,異常于起初數學模板和基本參數資料等情況,AI對集成電路CPU一直不有特別強列的使用需求,實用的CPU集成電路CPU就能供給充分的運算程度。假如現下在校這篇一這篇的你,小米5手機或線上里都是CPU集成電路CPU。后會致使高凊視頻圖片和玩游戲文化產業的最快快速發展壯大,GPU(圖型CPU)集成電路CPU具有在短精力內的快速發展壯大。鑒于GPU有大量的方式運算標段采用治理基本參數資料,專屬高并行加工處理型式,在治理圖型基本參數資料和繁雜數學模板等方面比CPU更有優勢,又鑒于AI深層次學會的模板基本參數多、基本參數資料總量大、運算量大,從始一段段精力內GPU當作了CPU,形成起初AI集成電路CPU的發展趨勢。不過GPU必竟而是平面圖形補救器,不能好一點使用于AI廣度借鑒的存儲電子器件,自燃存在的不到,表示動作的詞在實施AI軟件使用時,其并行性形式的功效不可能足夠起,引致高萬元產值能耗高。與此同一時間,AI技術設備的軟件使用亟須上漲,在培養、醫遼、無人售貨駕使等行業都能得到AI的痕跡。不過GPU存儲電子器件過高的高萬元產值能耗不可能足夠高新產業的供需,對此昭然若揭的是FPGA存儲電子器件,和ASIC存儲電子器件。那么的這兩者單片機芯片的技術應用的特點分別為是啥子呢?又有啥子是指性的物品呢?“萬能芯片”FPGA
FPGA(Field-Programmable Gate Array),即“直播可程序編寫程序門陣列”,是在PAL、GAL、CPLD等可程序編寫程序元器件封裝的依據上進一部提升的產品。
圖 Xilinx的Spartan系列FPGA芯片
專用集成電路ASIC
在AI產業鏈選用大大小起源于過后,運用FPGA一種好并行性來計算的常用集成塊來實行加快,是可以預防研發部門ASIC一種定制化集成塊的高支出和危害性。但正如我門方才說到的,鑒于專用電源集成ic的定制緣由而非主要專門針對的深度神經網絡了解,以至于FPGA無奈存在的耐磨性、顯卡功耗等各方面的關鍵話題。跟隨著機器自動化應運投資額的變大,同類話題將必將明顯。與其說,我門對機器自動化很多的美好幸福個人規劃,都要電源集成ic追趕機器自動化在短時間內成長的步調。要電源集成ic跟得上,也會為機器自動化成長的關鍵話題。所有,跟著近兩年手動成本自動化神經網絡算法和操作各個領域的快捷經濟經濟發展,及及研發項目管理上的成就和施工工藝上的急劇完善,ASIC電子器件也在變為手動成本自動化測算電子器件經濟經濟發展的主流產品。ASIC電源單片機集成塊是專門針對某個需求量而制作的專業化電源單片機集成塊。即使光榮犧牲了基礎性,但ASIC就算是在性、能耗都是量上,都比FPGA和GPU電源單片機集成塊有優質,越來越是在都要電源單片機集成塊同時要具備高性、低能耗、小量的轉動端儀器上,這種電話。雖然,由于公用性低,ASIC單片機集成塊的高產品研發的成本也將會會有高安全風險。可是要遵循專業市場基本要素,ASIC單片機集成塊說真的是服務行業的發展前景大社會發展趨勢。為有什么這般說呢?而是從工作器、確定出來機到無人值守化座駕車子、無人值守化機,再到智慧家庭的各種廚電,萬部的設施應該構建人工客服電話智慧確定出來實力和認知交互性實力。出至對24小時性的標準要求,或者康復訓練的數據私密照片等了解,這樣的實力不容能完成依賴性云空間,務必要有當地的薄厚件條件電商平臺承載。而ASIC基帶芯片高功能、低功率、小空間的性能剛好能無法這樣的需要量。ASIC芯片市場百家爭鳴
2016,英偉達顯卡分享了專門針對在加快和提升AI運算的Tesla P100心片,但是在2018年版本升級為Tesla V100。在來魔鬼訓練很大規模神經系統微信網絡對三維模型時,Tesla V100多為廣度掌握相關的對三維模型來魔鬼訓練和判斷應運提供了高達模型1210萬億次每秒的張量運算(張量運算是AI廣度掌握中最較為常用到的運算)。因此在極高機械效能機制下,Tesla V100的能耗實現300W,盡管機械效能強盛,但也根本困惑是顆“核彈”,所以太費電了。
圖 英偉達Tesla V100芯片

圖 谷歌TPU芯片

圖 Novumind的NovuTensor芯片
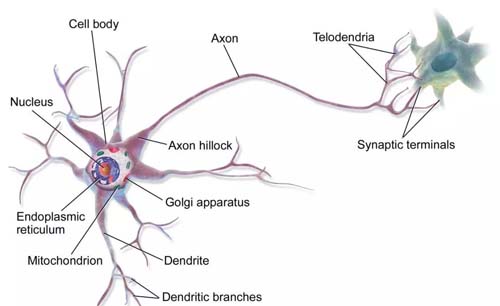
圖 神經元結構
類腦芯片
如句子一開始要說,現有那些電子設備,包涵以下聊到的那些處理芯片,都針對馮·諾依曼框架。其實一種體系結構往往十全十美。將CPU與存儲空間拆開的設計制作,越多越會促使即是的馮·諾伊曼難題(von Neumann bottleneck):CPU與存儲空間區間內的資源發送率,與存儲空間的儲存量和CPU的崗位熱工作效率比起都是小,于是當CPU須要在極大的的資源上履行些簡單標志位時,資源發送率就淪為總布局熱工作效率是比較嚴重的限制。如果你要工業化生產人工處理智慧集成電路芯片,現在有的專業人員就回歸祖國疑問自身,就開始仿照人的大腦的架構。人腦子內有過一千億個中樞腦感覺面神經元,有時其中一個中樞腦感覺面神經元都經過成千幾十萬個突觸與相關中樞腦感覺面神經元聯接,形成了全新龐大集團的中樞腦感覺面神經元漏電開關,以劃分式和并發式的方式方法傳遞警報,很大于很大綜合規模的并行性計算方法,但是礦池好強。人腦子的另其中一個特質是,不腦子的其中一個部件都一直都在事業,于是綜合能源消耗很低。這品種腦基帶電子器件跟一般式的馮·諾依曼網絡架構有所差異,它的手機存儲空間、CPU和溝通的技巧構件是是集成化在一件,把數值加工器視作感覺感覺精神末梢系統元,把手機存儲空間身為突觸。除此認為的英文,在類腦基帶電子器件上,相關信息的加工是在本地服務服務采取,還因本地服務服務加工的數據統計量并不是很大,一般式來計算機系統手機存儲空間與CPU期間的瓶頸問題不復會有了。同樣,感覺感覺精神末梢系統元但凡收到其他的感覺感覺精神末梢系統元發來參觀的脈沖信號,這類感覺感覺精神末梢系統元也會同樣做動作,故此感覺感覺精神末梢系統元期間行便宜方便地充分溝通的技巧。在類腦IC處理器的研發部門上,IBM是服務業內的優先者。2015年IBM推送了TrueNorth類腦IC處理器,這個IC處理器在內徑只剩下幾CM的方寸個人空間里,智能家居控制型了4096個內核、50萬個“中樞神經元”和2.5億元個“突觸”,能效比只剩下不倒70毫瓦,幾乎是高智能家居控制型、低顯卡功耗的無暇特別。
圖 裝有16個TrueNorth芯片的DARPA SyNAPSE主板


